Proj 1
Placeholder summary describing the project focus and impact.
PythonDataVisualization
03. Projects
Scientific machine learning pipeline for fast flavor instability detection in neutrino astrophysics. This is the same project presented in my DNP poster.
This classifier turns simulation-derived neutrino data into a stability signal: FFI present vs stable. The model is intentionally compact and interpretable, and every training run writes out plots and metrics so the physics story stays traceable from raw data to final decision thresholds.
The training pipeline is built around reproducible configs, deterministic splits, and threshold sweeps that emphasize physics-meaningful tradeoffs (precision vs recall) rather than a single default cutoff.
The DNP poster covers the same data sources, model family, and evaluation logic. Use it as a compact overview while the sections below go deeper into the pipeline and results.
View DNP Poster PDFFour simulation-derived NPZ datasets are pooled into a single training set. Each file provides 27-dimensional features alongside binary instability labels, so the model sees multiple regimes and learns a shared decision boundary rather than a single-scenario heuristic.
A multi-layer perceptron ingests standardized features and is trained with BCEWithLogitsLoss plus per-sample weights. The schedule includes warmup, reduce-on-plateau learning rate decay, and early stopping. Metrics are logged per epoch at a 0.5 threshold, then swept from 0.01 to 0.99 to maximize F1.
Loss curves show steady convergence across seeds and a stable validation floor. The F1 threshold sweeps reveal a broad optimum, indicating the classifier remains reliable across a range of decision thresholds rather than a single fragile cutoff. These runs correspond to the plots below.
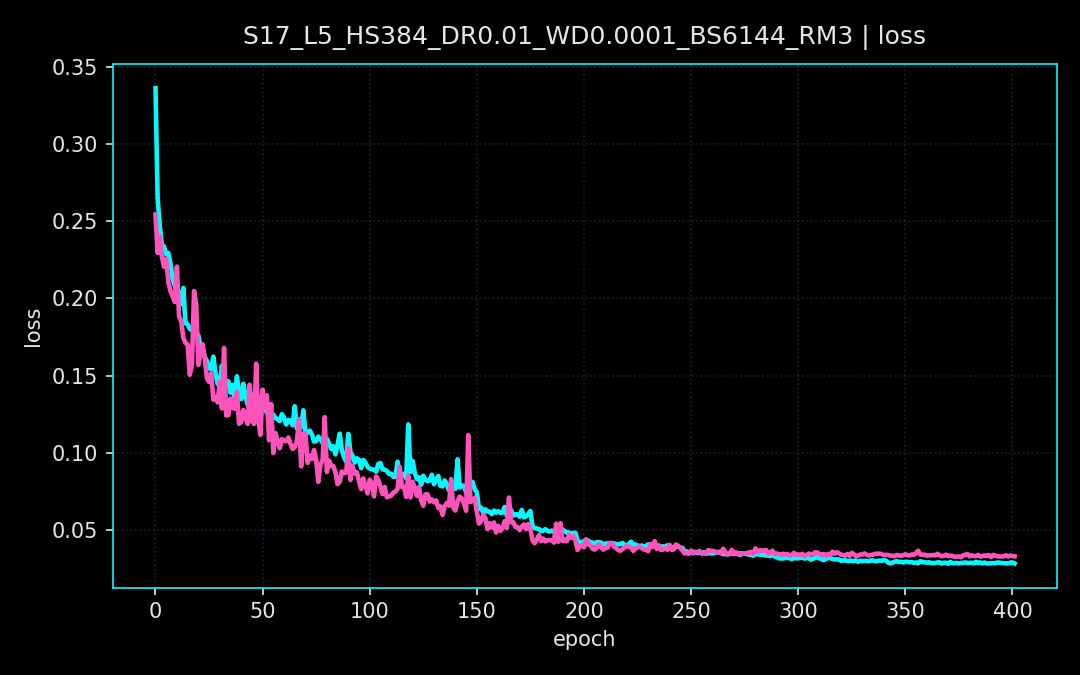
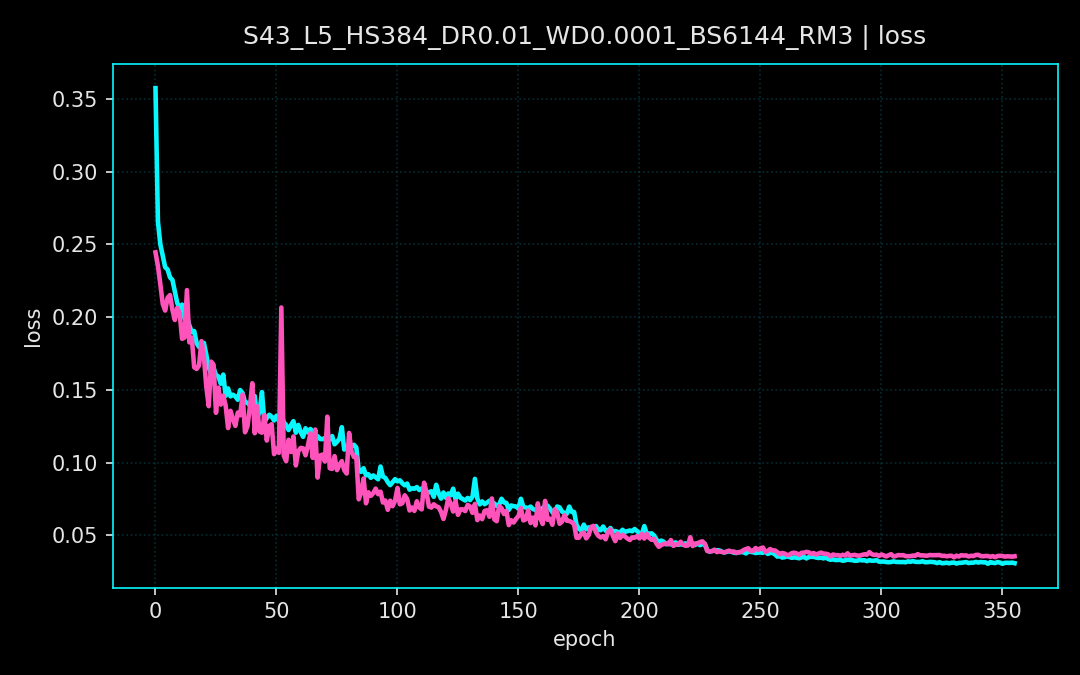
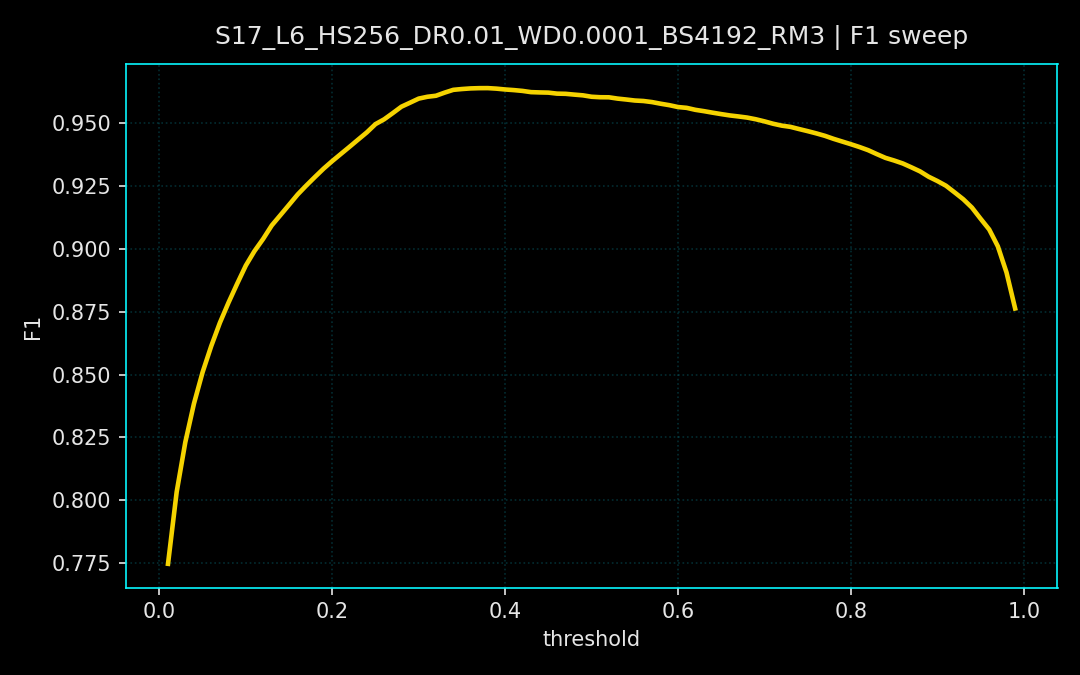
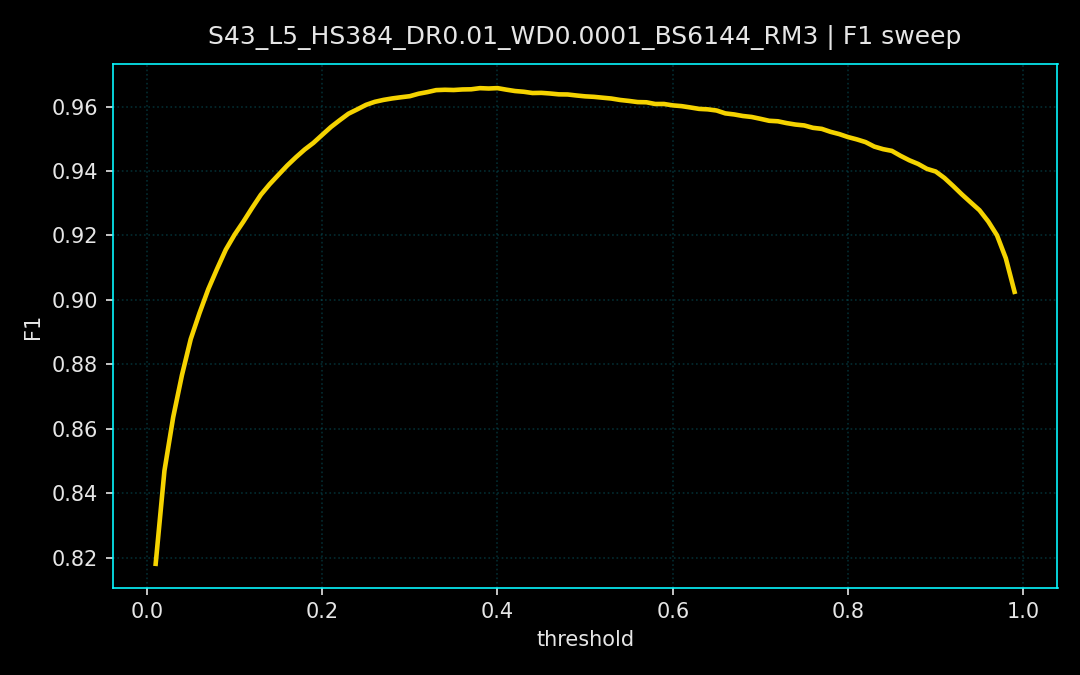
03. Projects
A lightweight PPO pipeline that learns to steer a single qubit across the Bloch sphere with minimal time and control energy. Built for interpretability and quick iteration without heavy frameworks.
The environment simulates pure-state qubit dynamics in Bloch form with a goal-conditioned observation that includes the current and target states. Actions map to bounded control amplitudes, and an RK4 integrator evolves the Bloch vector while enforcing normalization.
PPO is implemented from scratch for transparency. The buffer computes generalized advantage estimates, then the actor-critic updates with clipped policy loss, entropy regularization, and value loss.
The starter repo includes training scripts, evaluation rollouts, and plotting utilities for fidelity, control pulses, and Bloch-sphere trajectories.
View GitHub RepoEach episode samples an initial and target Bloch vector separated by a minimum angle. Observations are goal-conditioned (current + target state), and optional domain randomization perturbs drift and control amplitude to improve robustness.
PPO collects rollouts across parallel environments, computes GAE returns, and updates a compact actor-critic network with clipped policy ratios. Entropy regularization preserves exploration while the value head stabilizes training.
Evaluation rollouts show the agent quickly increasing fidelity while keeping control pulses smooth. The Bloch trajectory arcs toward the target, and the component plots confirm convergence of x, y, z to the desired state.
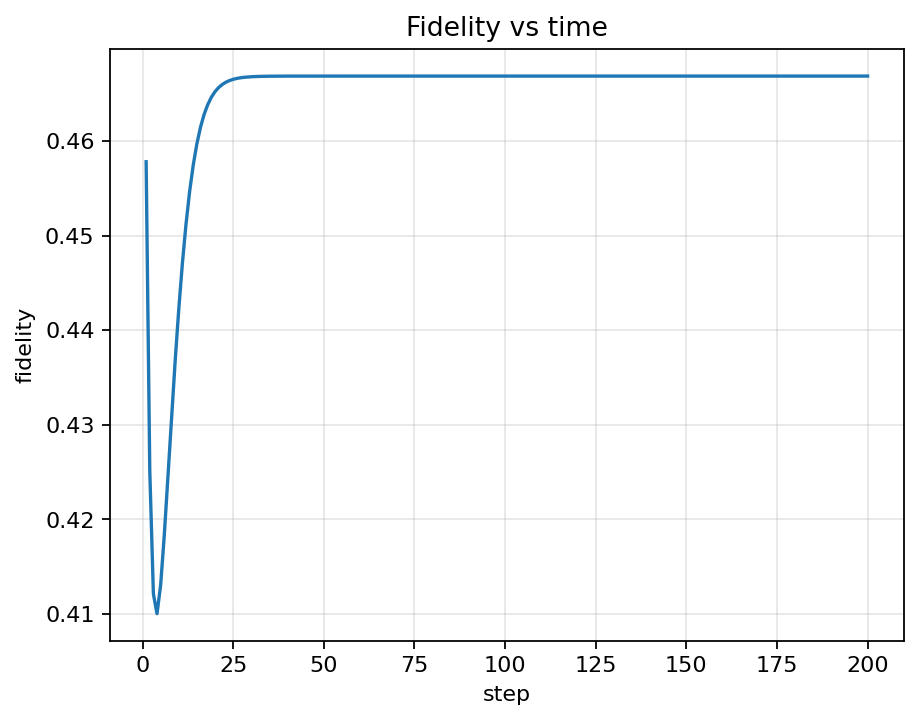
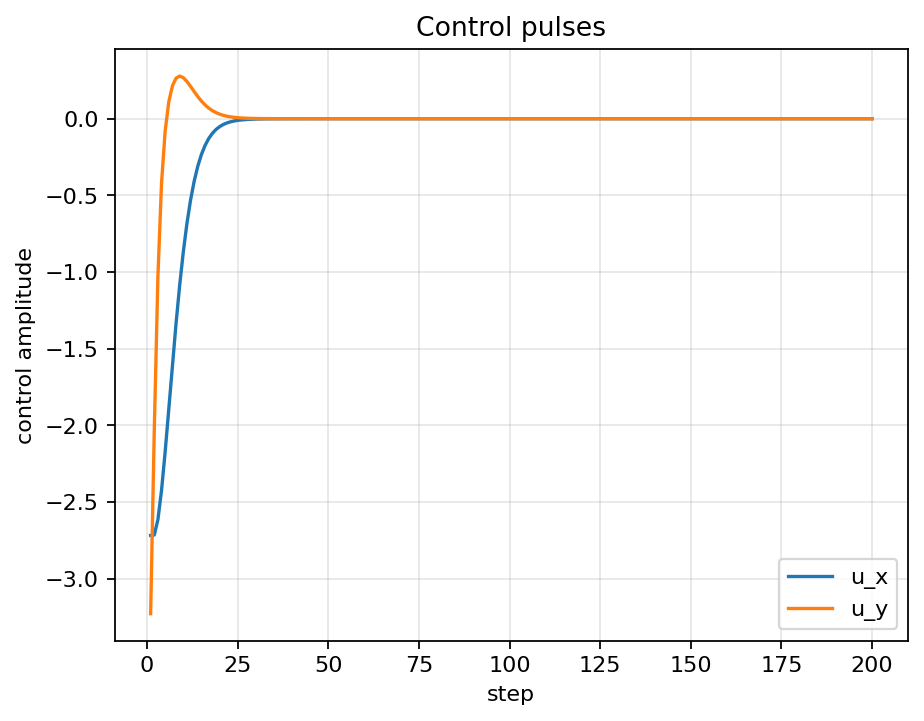
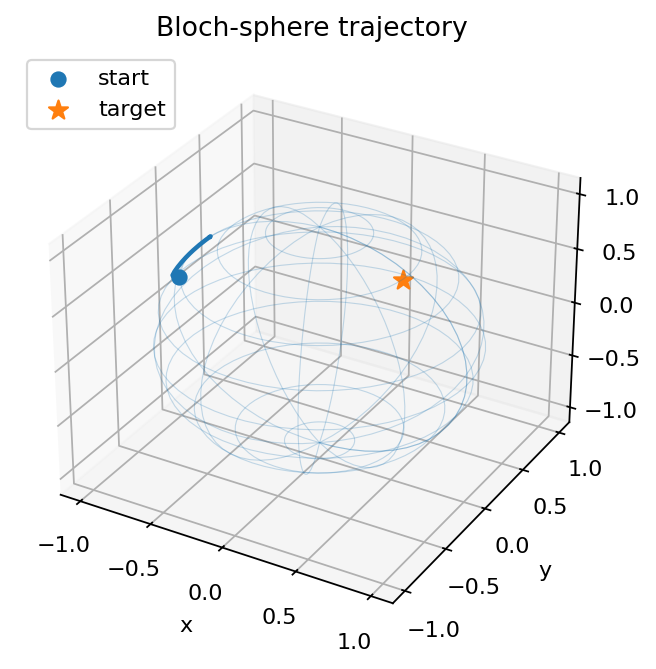
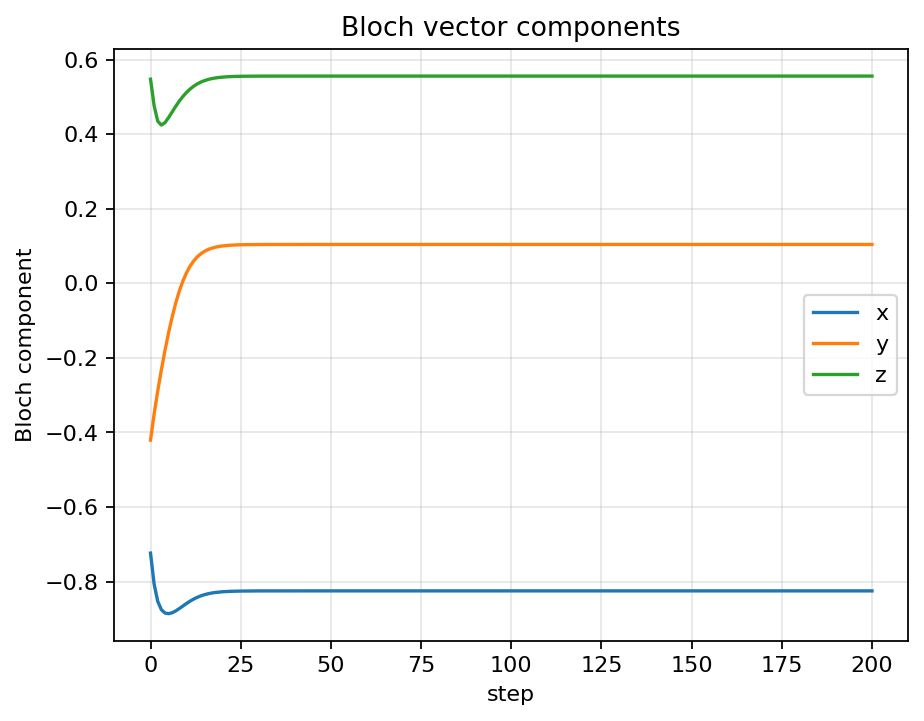
Placeholder summary describing the project focus and impact.
Placeholder summary describing the tools, methods, or outcomes.
Placeholder summary describing the scope and key learning.
Placeholder summary describing a standout result or collaboration.